|
Scientific and reference databases on the Web are a primary source of information.
However, the data is subject to continuous change and often only the most recent versions are
preserved. For many database providers it has become common
practice to overwrite existing database states when changes
occur and regularly publish new releases of the data on the Web.
Failure to archive earlier states of the data may lead to
the loss of scientific evidence, and the basis of findings may no
longer be verifiable. Recently, some database providers have
initiated archiving efforts that allow to view entries exactly
as they were in the past.
Database archiving is, however, not only important for verification of
scientific findings. Consider the fact that nearly every dictionary,
gazetteer, encyclopaedia or reference manual that one traditionally
found on the reference shelves of libraries is now available on the
Web. In many cases one is interested not just in an old version of
the data, but one is interested in forming queries over the history of the data.
A prime example of this is the CIA World Factbook,
possibly the most widely used source of demographic information. Over the past 18 years the Factbook has
moved from an annually printed distribution to a web resource. Over
that period it has kept a remarkably uniform structure. Apart from one
or two spreadsheets that contain only a small portion of the data,
there appears to have been no attempt to bring all past versions into
a common form. In fact, although all past versions are available on
line (the printed versions have been transcribed into a variety human
and machine-readable formats), it is quite hard even to find all these
versions. Temporal queries such as ''How did electricity generation
in China change over the past 15 years?'' can be extremely valuable,
but to answer such queries using the data in its current state is
extremely time-consuming. This emphasises the need to have both a
uniform archival representation and a query language in order to make
temporal queries like this easy to formulate and efficient to execute.
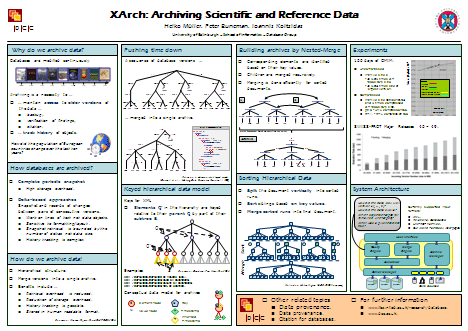
A system trying to archive evolving databases on the Web faces several
challenges. First and foremost, the systems needs to be able to efficiently
maintain and query multiple snapshots of ever growing databases. Second,
the system needs to be flexible enough to account for changes to the database
structure and to handle data of varying quality. Third, the system needs to
be robust and invulnerable to local failure to allow reliable long-term
preservation of archived information. Our archive management system XArch
addresses the first challenge by providing the functionality to maintain,
populate, and query archives of database snapshots in hierarchical format.
In our ongoing efforts we are currently improving XArch regarding archiving
evolving databases, and databases of varying quality.
The following poster gives an overview of the techniques and architecture behind XArch.
|