|
Based on the algorithms in Buneman et al. 2004, we implemented the
archive management system XArch (Müller et al. 2008). The system allows
one to create new archives, to merge new versions of data into existing archives,
and execute both snapshot and temporal queries using a declarative query language.
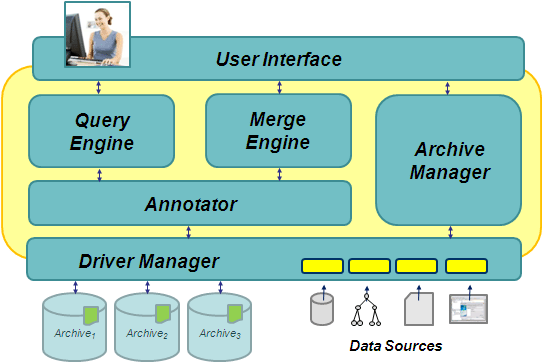
The overall system architecture is shown in the figure below.
|
|
We introduce the concept of IO driver to abstract from the data model of documents
and data sources. A driver is basically a wrapper around any tool that
generates XML output. Instead of writing the output to a file the driver
calls the appropriate methods of a provided callback handler that
transform elements, attributes and text into internal node objects. We
currently provide several different drivers: an XML driver based on the
Simple API for XML (SAX), and drivers for exporting
data in a relational database based on XML publishing techniques.
We currently use XML as the storage format of archives. Element nodes and timestamps
are represented as XML elements. Text nodes are XML strings.
|
|
Creation and deletion of archives is handled by the Archive Manager.
|
|
The Annotator assigns key values to nodes based on relative keys (Buneman et a., 2002)
using the algorithm described in Buneman et a., 2004.
|
|
The Merge Engine merges a new version of data into a given archive.
When dealing with serialised hierarchical data formats, like XML,
one usually employs a depth-first method to access the data. The
problem with the nested merge approach described in Buneman et a., 2004
is that it does not manifest this natural access pattern. The reason
is that in order to identify correspondences between children of
merged nodes, one must read the complete subtrees of each such node.
Thus, numerous passes over the data may be required to compute the
nested merge outcome. If, however, the datasets are ordered according
to their keys the situation is greatly alleviated. Assuming an
ascending order, whenever two nodes are merged, one can follow a
more traditional merge approach: sequentially scan the nodes' children
and compare their values. The child with the smaller value is output
(including the complete subtree rooted underneath it) to the new archive,
after being annotated with the proper timestamp. This procedure ensures
a total ordering among all children of any node. In case nodes with equal
key values are encountered, we recursively merge their children. The
described procedure ensures that the archive is always sorted on node
keys. More importantly, only the incoming version has to be sorted in
advance to performing nested merge.
The common approach for sorting large datasets in external memory is
external merge sort. External merge sort splits the dataset into multiple
sorted runs during a single pass over the data. Runs are then merged to
generate the sorted output. Depending on the number of runs created in
the first phase, merging may require multiple passes over the data.
Splitting hierarchical data is, however, not straightforward. We
developed an algorithm that ''vertically'' splits a hierarchical document
into sorted runs (Koltsidas et al, 2008). We start by reading the portion
of the document that fits into main memory and sort the data. Unkeyed
nodes are pushed to the end of their parent node in document order. We
output the tree as a sorted run. We keep all those node in memory whose
children have not been read completely and read the next portion of the
tree. By duplicating incomplete nodes we ensure that each run represents
a proper tree rooted under the same original root node. Sorted runs are
then merged to form the sorted document. Our experiments show that our
algorithm is superior to existing bottom-up approaches, that collapse the
tree into files of sorted subtrees. The reason is that the reconstruction
phase of such algorithms accesses the subtree files in random order,
which incurs an I/O penalty.
We utilize our sorting algorithm and modify the nested merge algorithm
in Buneman et a., 2004 to overcome restrictions on archive sizes.
After assigning key values to the nodes in the archive and the input
document, we sort the document on node key values and merge the archive
and the sorted document into a new archive version. We merge sorted runs
directly with the archive whenever the number of runs allows to be merged
in a single pass.
|
|
Our declarative query language XAQL allows retrieval of particular data versions,
tracking of object history, and retrieval of timestamps representing the sequence of
versions when a given condition was valid. XAQL is oriented toward OQL
since archives are not arbitrary XML documents, but follow a fairly regular structure
given by the key specification. We consider nodes as objects and an archive as a nested,
timestamped object hierarchy. Timestamps become a first class concept in XAQL.
The general syntax of a XAQL query is as follows:
|
| SELECT [TIMESTAMP | * | expr] |
| FROM {CHANGES IN | UNCHANGED} name {LCP path-expression} {KEEP KEY VALUES} |
| {WHERE condition {COINCIDE}} |
|
The SELECT and FROM clause are mandatory, all other parts
are optional. The SELECT clause specifies the nodes in the query
result. The FROM clause specifies the archive to be queried.
The WITH clause allows definition of object variables that are used in select statements
and where conditions. Temporal projection is enabled by the VERSION
clause. When specified, a query is evaluated only on those versions in the
archive that are listed in the given timestamp. The WHERE clause
filters nodes based on a given condition. XAQL currently allows conjunctions
of conditions on values of text nodes or unkeyed subtrees. Coincidence
queries are supported by the keyword COINCIDE in the WHERE
clause. We further support predicates on the history of nodes and subtrees.
Predicate HAS CHANGES is true if the subtree rooted under a node
has changes in the considered versions. The WAS MODIFIED predicate
is true if an element itself was changed, i.e., it does not inherit its
timestamp from the parent.
The figure below shows three example XAQL queries for the Factbook. The first
query shows how the total number of airports in Australia changed between 2000 and 2008.
The second query retrieves the
name and land area of all European countries with changes to the land area between
2000 and 2008. The predicate HAS CHAGES evaluates to true if the specified node or
one of it's sub-nodes is timestamped. The third query retrieves a timestamp of all
Factbook releases that list Tony Blair as Prime Minister of the U.K..
|