|
Curated databases are predominantly kept in well-organised hierarchical
data formats having a key structure that provides a canonical identification
for each element by the path in which it occurs and the values of some of
its sub-elements. Our archiver uses this property to efficiently maintain
multiple versions of the same dataset. We distinguish between two different
types of nodes in a hierarchy: (i) element nodes having a label,
and (ii) text nodes having a value. Only element nodes may occur
as internal nodes.
|
Element keys are defined using key constraints that are
similar to keys for XML defined in Buneman et al. 2002.
A key specification K is a set of key definitions k = (q, s), where
q is an absolute path of element labels and s is a key value expression. Each
key definition (q, s), specifies a set of elements reachable by path q and defines how
the key value is derived from the elements subtree. We distinguish between three types of key value expressions:
- EXISTENCE
- SUBTREE
- VALUES
All element keys are relative keys, i.e., the key value uniquely identifies an
element among its siblings. Elements that are keyed by existence are keyed
by their label. Elements that are keyed by subtree are uniquely identified
by the value of their whole subtree (see Buneman et al. 2004 for
definitions of subtree values). For elements e that are keyed by values
an additional set of relative path expressions is given. Each path expression p specifies an element in the subtree of e whose value
is used as part of the key value for e. These values are referred to as
key path values.
|
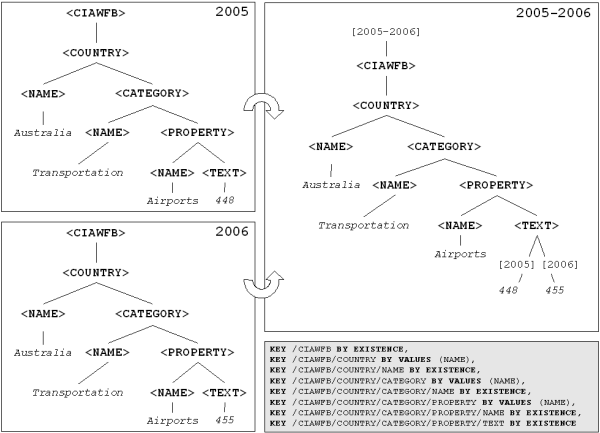
The figure below shows (part of) the key specification for the Factbook, stating that countries, categories,
and properties are identified by their respective name element, whereas
name and text are keyed by existence, i.e., they appear only once
among the children of their parent.
|
|
In Buneman et al. 2004 a nested merge approach to
archiving is developed that efficiently stores multiple versions of
hierarchical data in a compact archive by ''pushing down'' time and
introducing timestamps as an extra attribute of the data. Archives of
multiple database versions are generated by merging the versions into
a single hierarchical data structure. Corresponding elements in
different versions are identified based on their key values. The archiver
stores each element only once in the merged hierarchy to reduce storage
overhead. Archived element and text nodes are annotated with timestamps
representing the sequence of version numbers in which the node appears.
The above figure shows the resulting archive from merging the two
examples from the Factbook in 2005 and 2006. Timestamps are shown in
square brackets as edge labels of their respective nodes. Note that
we only show (and materialize) the timestamps for those nodes whose
timestamp differs from their parent's one.
The nested merge approach
has several advantages regarding storage space, retrieval of database
versions, and tracking of object history. For example, the 19 annual
releases of the Factbook between 1990 and 2008 contain a total of
3,770,468 nodes whereas the resulting archive contains only 765,355
nodes. Although the information in the Factbook changes quite significantly
in between the years, there is reduction in storage space is from 95.7 MB
for the set of individual releases to 39.1 MB for the archive (from 19.1 MB
to 6.8 MB if the files ares stored in GZIP-format).
|

